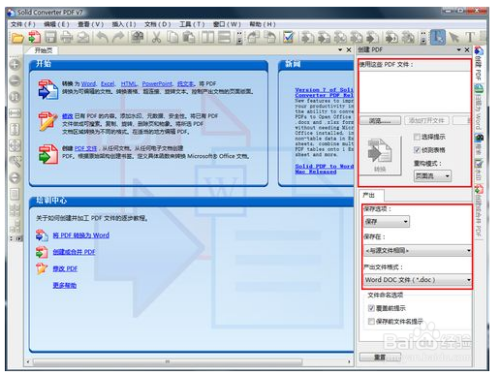
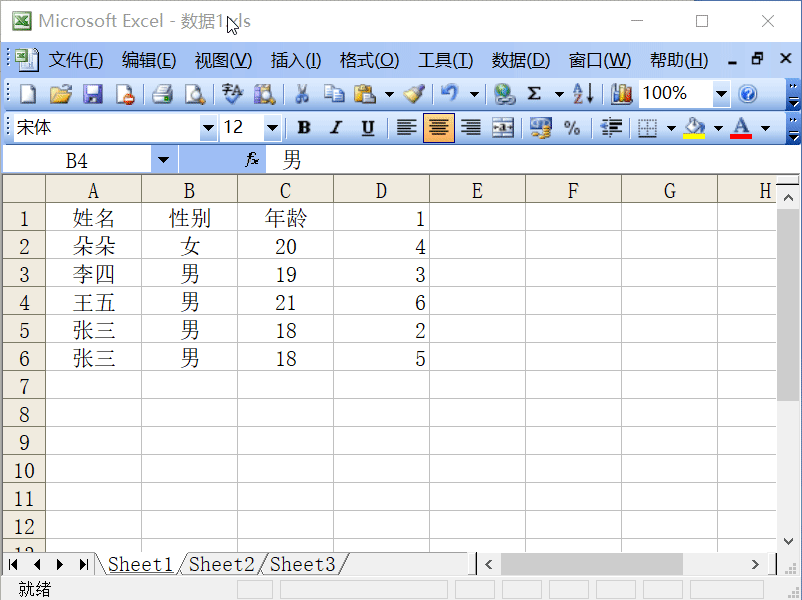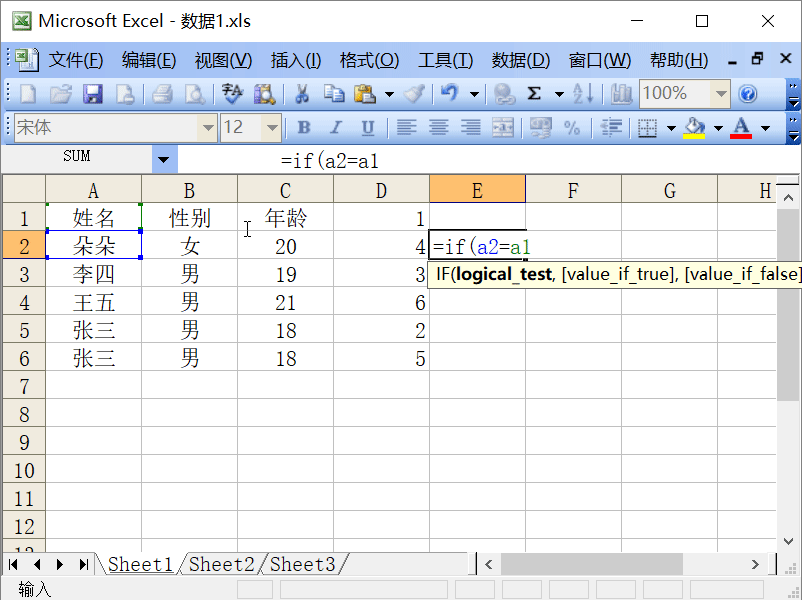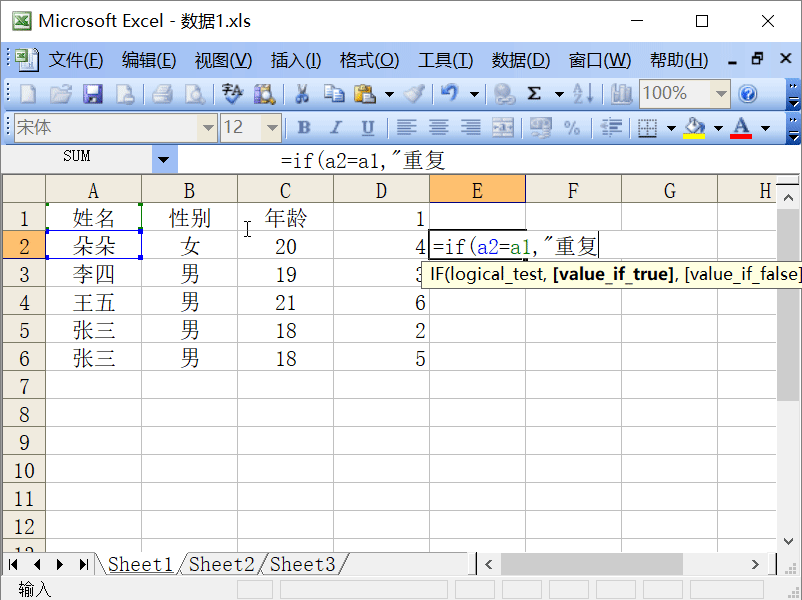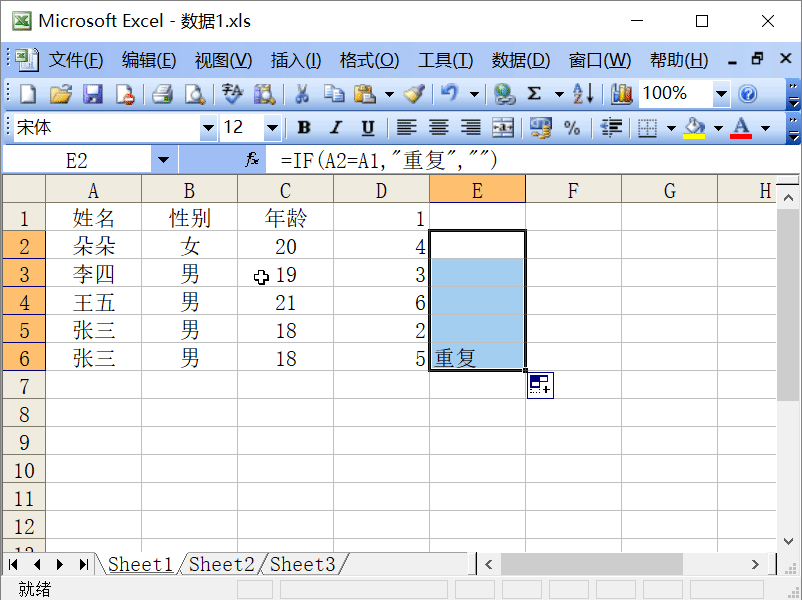
在数字化信息时代,PDF和Excel作为两种常见的文件格式,被广泛使用于办公、学习、研究等多个领域。将PDF文档转换为Excel表格的需求日益增加,这要求我们掌握一些基本的转换技巧。本文将从技术角度和实际操作两个层面,对如何将PDF转成Excel表格进行详细介绍。
我们需要了解PDF到Excel转换的技术原理。PDF是一种压缩且加密的文件格式,而Excel则是一个电子表格软件,支持文本、图像、声音等多种数据类型。要将PDF转换成Excel,需要借助专门的工具或编写脚本来提取PDF文件中的文本内容。
以OCR(Optical Character Recognition)技术为例。OCR是光学字符识别技术,它可以通过扫描纸质文档,将其中的文字信息转换成可编辑的文本格式,例如纯文本或HTML格式。在处理PDF文件时,可以利用OCR技术从图片中提取文本,并将其导入Excel。
我们可以利用Python等编程语言结合第三方库,如`PyPDF2`、`Pdf2exe`等,实现PDF到Excel的自动化转换。以下是一个使用Python和`PyPDF2`的示例代码:
import PyPDF2
import os
def convert_pdf_to_excel(input_folder, output_file):
for file_name in os.listdir(input_folder):
if file_name.endswith('.pdf'):
pdf_file = input_folder + '/' + file_name
with open(pdf_file, 'rb') as pdf_file:
reader = PyPDF2.PdfFileReader(pdf_file)
text = ''
for page_num in range(reader.getNumPages()):
text += reader.getPage(page_num).extractText()
这里假设我们已经得到了包含所有文字内容的字符串text
with open(output_file, 'w', encoding='utf-8') as excel_file:
writer = openpyxl.Workbook()
writer.add_sheet('Sheet1')
for line in text.split('
'):
writer.cell(row=1, column=5, value=line) 假设Excel的第一行第一列为A1,其他位置为对应的列索引
writer.save(output_file)
print("转换完成")上述代码展示了一个基本的PDF转Excel过程。首先遍历输入文件夹中的所有PDF文件,然后读取每个PDF文件的内容并提取出其中的文本信息。我们将提取出的文本写入一个新的Excel文件中。需要注意的是,这个示例代码仅适用于简单的场景,对于复杂的转换需求或者大量数据的情况,可能需要进行进一步的优化和调整。
此外,还可以考虑使用在线转换工具。这些工具通常提供用户友好的界面,可以上传PDF文件并自动将其转换为Excel格式。但是需要注意的是,这类工具的准确性和安全性可能会有所欠缺,因此在选择使用时需要谨慎。
将PDF转成Excel的过程涉及到了多种技术和方法。通过使用OCR技术、编程脚本以及第三方库等手段,可以实现PDF到Excel的自动化转换。同时,也需要注意选择适合自己需求的转换方式和工具,确保转换结果的准确性和可靠性。随着技术的不断发展,相信未来会有更多高效、准确的转换工具出现,以满足人们日益增长的需求。