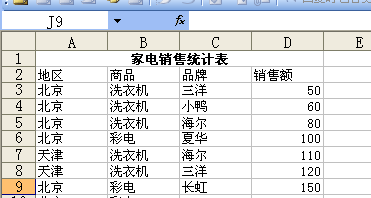
在数据分析和数据科学领域中,Python 作为一种功能强大的编程语言,其灵活性和易用性使其成为处理各种类型数据的首选工具之一。其中,Excel作为一种常见的电子表格格式,经常用于存储、管理和分析各种数据。因此,掌握如何在 Python 中导入 Excel 文件对于数据科学家和分析师来说至关重要。本文将详细阐述如何在 Python 环境中导入 Excel 文件,包括必要的库安装、数据读取以及常见问题解决。

我们需要了解几个关键点:
- 选择适合的库:在 Python 中,有多种库可以用于处理 Excel 文件,其中最常用的是 pandas 和 openpyxl。pandas 提供了强大的数据处理功能以及与 Excel 文件交互的能力,而 openpyxl 则更侧重于操作和写入 Excel 文件。
- 安装所需库:确保已经安装了所需的 Python 库。如果没有安装,可以使用 pip 进行安装。
- 数据读取方法:根据具体需求选择合适的方法读取 Excel 文件中的数据。例如,使用 pandas 的 read_excel 函数可以很方便地读取 Excel 文件。
- 处理和分析数据:导入数据后,可以使用 pandas 提供的各种功能对数据进行处理和分析。
- 保存和导出结果:处理完成后,可以将结果重新保存到新的 Excel 文件中或其它格式的文件中。
详细步骤和示例
我们逐步详细说明如何在 Python 中导入 Excel 文件,并通过一个具体的例子来展示整个过程。
1.安装所需库
确保已安装 pandas 和 openpyxl。如果没有安装这些库,可以使用下面的命令进行安装:
pip install pandas openpyxl
2.导入库并读取 Excel 文件
我们编写一个简单的脚本来演示如何使用 pandas 读取 Excel 文件。假设有一个名为 data.xlsx 的文件,其中包含一些简单的数据集。
import pandas as pd 定义 Excel 文件路径 file_path = 'data.xlsx' 使用 pandas 的 read_excel 函数读取 Excel 文件 df = pd.read_excel(file_path) 显示前几行数据 print(df.head())
3.数据预处理
导入数据后,可以进行各种预处理操作,例如检查缺失值、数据清洗等。以下是一些常用的数据预处理方法:
检查是否有缺失值 print(df.isnull().sum()) 填充缺失值 df.fillna(method='ffill', inplace=True) 删除重复行 df.drop_duplicates(inplace=True)
4.数据分析和可视化
处理完数据后,可以进行数据分析和可视化。这里以一个简单的统计描述为例:
计算每个列的统计描述信息 describe = df.describe() print(describe)
5.保存和导出结果
我们可以将处理后的结果保存回一个新的 Excel 文件中:
保存到新的 Excel 文件中
df.to_excel('processed_data.xlsx', index=False)
总结
通过以上步骤,我们展示了如何在 Python 中导入和处理 Excel 文件。使用 pandas 库,可以轻松实现数据的读取、预处理、分析和保存。这不仅简化了数据操作流程,还极大地提高了工作效率。
掌握如何在 Python 中导入 Excel 文件是进行数据分析的基础技能之一。无论是学术研究还是实际工作中的数据挖掘,这一技能都是必不可少的。希望通过本文的介绍,能够帮助你在数据分析的道路上更加得心应手。